Erich Focht
Introduction
py-veo is a Python module implementing the VEO API for Vector Engine Offloading, AKA veoffload. It allows the use of the VE from Python programs, even interactively and via IPython or Jupyter notebooks. VE “kernels” must be written in C, C++ or Fortran.
I wrote py-veo a year ago, presented it first at ISC 2018 but the project was quiet for the past half year. This post presents some recent changes and extensions of the API as well as the new option to build VE kernels from inside Python code.
Background
The NEC Aurora Tsubasa Vector Engine (VE) is a very high memory bandwidth vector processor with HBM2 memory in the form-factor of a PCIe card. Currently up to eight VE cards can be inserted into a vector host (VH) which is typically a x86_64 server.
The primary usage model of the VE is as a standalone computer which uses the VH for offloading its operating system functionality. Each VE card behaves like a separate computer with its own instance of operating system (VEOS), it runs native VE programs compiled for the vector CPU that are able to communicate with other VEs through MPI.
A second usage model of VEs lets native VE programs offload functionality to the VH with the help of the VHcall mechanisms. The VH is used by the VE as an accelerator for functions it is better suited for, like unvectorizable code.
The third usage model is the classical accelerator model with a main program compiled for the VH running high speed program kernels on the VE. A mechanism for this usage model is the VE Offloading (VEO) library provided by the veofload and veoffload-veorun RPMs.
Architecture
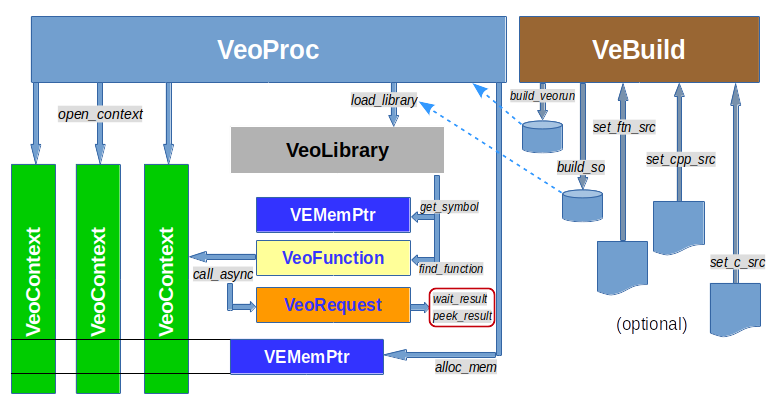
A VeoProc object corresponds to one running instance of the veorun
VE program that controls one address space on a VE and enables its
user to offload VE kernels. Each VE the user wants to use should have
one VeoProc instance.
VeoLibrary represents a loaded dynamically shared object inside a
VeoProc process. VE kernels can also be linked statically into the
veorun program, that is a special case of a VeoLibrary.
A VeoFunction object represents a VE kernel (function) inside a
VeoLibrary. Functions need to be located inside a library by
invoking the VeoLibrary obect’s find_function() method, explicitly
or implicity, by accessing an attribute of the VeoLibrary that is
named like the expected function.
Memory buffers can be allocated inside the VeoProc, they are
represented by VEMemPtr objects. These objects can be passed as
arguments to syncronous or asynchronous VE-VH memory copying
calls. Symbols inside VeoLibrary libraries loaded into the VeoProc
can also be represented as VEMemPtr objects.
Inside the VeoProc process one or more VeoCtxt objects are the
actual worker threads on the VE. The number of contexts should be
limited to the number of cores of the VE. When using OpenMP VE
kernels, the number of contexts should be one for each VE. Contexts
have command and result queues which serialize requests sent to
them. Contexts share the memory of their VeoProc process.
A VeoFunction invoked on a VeoCtxt returns a VeoRequest
object. The VeoRequest can be waited for (synchronous wait) or
“peeked” at for asynchronous checks. A VeoFunction takes up to 32
arguments (currently artificially limited in VEO) and can pass back
results, 64 bits as the function return value or on the function’s VE
stack. The VE stack can also be used for passing arguments that are
accessed by reference from the function (like all arguments in
Fortran).
Simple VE kernels can be represented as strings inside Python and use
the VeBuild class for compiling and building the dynamically shared
VE library or veorun excutable. This is also an easy method to start
playing with code on the Vector Engine.
A Simple NUMPY Example
Let’s consider the following simple VE kernel that calculates the average of a vector of double precision values:
double average(double *a, int n)
{
int i;
double sum = 0;
for (i = 0; i < n; i++)
sum += a[i];
return sum / (double)n;
}
This VE kernel must be compiled and linked as a dynamically shared object. We store the content into a file named average.c, compile and link it:
cat > average.c << EOF
double average(double *a, int n)
{
int i;
double sum = 0;
for (i = 0; i < n; i++)
sum += a[i];
return sum / (double)n;
}
EOF
/opt/nec/ve/bin/ncc -O3 -fpic -pthread -shared -o ve_average.so average.c
Now let’s prepare for calling the VE from a Python program test-average.py:
import os
import veo
# VE node to run on, take 0 as default
nodeid = os.environ.get("VE_NODE_NUMBER", 0)
proc = veo.VeoProc(nodeid)
ctxt = proc.open_context()
lib = proc.load_library(os.getcwd() + "/ve_average.so")
Here we first check whether the VE node ID was specified in the environment variable VE_NODE_NUMBER, if not, we use VE node 0. Next we create a process proc on the selected VE and a worker context ctxt. Lastly we load the previously created shared object into the proc process by calling its load_library() method.
Next let’s “find” the VE kernel function average inside the library and define its argument types and the return value’s type:
lib.average.args_type("double *", "int")
lib.average.ret_type("double")
When an unknown attribute of the VeoLibrary object is specified, it is considered to be a function inside the library, therefore it is searched and cached inside the VeoLibrary object.
The argument types must be declared as primitive data types or their pointers. Don’t specify variable names, as often done in C function prototypes!
Now let’s create a NUMPY vector a that shall be passed into the VE function:
# numpy is already imported with veo. no need to re-import it
np = veo.np
n = 100000 # length of random vector
a = np.random.rand(n)
Currently the vector a is located in the VH memory, inside the Python application’s address space. We need to transfer it to the vector engine into an appropriate buffer:
# allocate a buffer on the VE that can hold n doubles
a_ve = proc.alloc_mem(n * 8)
# synchronously transfer the data from a into the VE
proc.write_mem(a_ve, a, n * 8)
Asynchronous buffer transfers are also possible, they would need to be queued into the VeoCtxt. The asynchronous alternative below also requires to wait or peek for the request req:
# alternative async memory transfer command
req = ctxt.async_write_mem(a_ve, a, n * 8)
Finally let’s call the VE funtion and wait for the result:
# submit VE function request
req = lib.average(ctxt, a_ve, n)
# wait for the request to finish
avg = req.wait_result()
print("avg = %r" % avg)
When done, the buffer can be freed, anyway it would be released implicitly once the proc is cleaned up:
proc.free_mem(a_ve)
VeoCtxt can be closed by the close_context() method of the proc object, but that is actually done implicitly under the hood when the proc object is destroyed:
del proc
Same Example, With VeBuild
Using the VeBuild class we can fit the example from the previous section into just one Python file. This is often easier for little experiments or for using interactive Python notebooks like iPython or Jupyter.
The example below has been changed in some details, besides using the inlined C source for the VE, the NUMPY random vector a is passed on the stack into the VE kernel. This works for arguments that fit into the first 64MB page allocated for the VE kernel’s stack.
import os
from veo import *
bld = VeBuild()
bld.set_build_dir("_ve_build")
bld.set_c_src("_average", r"""
double average(double *a, int n)
{
int i;
double sum = 0;
for (i = 0; i < n; i++)
sum += a[i];
return sum / (double)n;
}
""")
ve_so_name = bld.build_so()
# VE node to run on, take 0 as default
nodeid = os.environ.get("VE_NODE_NUMBER", 0)
proc = VeoProc(nodeid)
ctxt = proc.open_context()
lib = proc.load_library(os.getcwd() + "/" + ve_so_name)
lib.average.args_type("double *", "int")
lib.average.ret_type("double")
n = 1000000 # length of random vector: 1M elements
a = np.random.rand(n)
print("VH numpy average = %r" % np.average(a))
# submit VE function request
req = lib.average(ctxt, OnStack(a), n)
# wait for the request to finish
avg = req.wait_result()
print("VE kernel average = %r" % avg)
del proc
With OnStack it is possible to pass in and out arguments that need to be accessed by reference. Python objects that support the buffer interface are supported as arguments of OnStack. The initialization syntax is:
OnStack(buff, [size=...], [inout=...])
with the arguments:
buff: is a python object that supports the buffer interface and is contiguous in memory.size: can limit the size of the transfer. If not specified, the size of the buffer is used.inout: the scope of the transfer, can beVEO_INTENT_IN,VEO_INTENT_OUTorVEO_INTENT_INOUT.
With VEO_INTENT_IN the Python buff object’s buffer is copied onto the VE stack right before calling the VE kernel. With VEO_INTENT_OUT the buffer is not copied in but copied out from the VE’s stack into the Python object’s buffer after the VE kernel has finished execution. VEO_INTENT_INOUT obviously copies data in before execution and out after.
Conclusion
The little examples show the basic usage of py-veo, how to define functions for the VE, allocate buffers, transfer memory and call VE kernels. For further steps please read the documentation on github in the project’s README.md github.com/SX-Aurora/py-veo and look into the little tests in the examples/ subdirectory.
… to be continued …