Erich Focht
Recently the RPM package libsysve has been added a library that can be used to accelerate the file IO bandwidth and latency. The SX-Aurora vector engine (VE) is offloading system calls to its Linux vector host. libveaccio is a quick and easy way with potential to significantly speed up the IO related data transfer between VE and VH. This post is motivated by the performance boost that can be reached in an easy way and by the presentation of Kawahara-san from the VEOS group, which I watched at the WSSP workshop in March 2019 at Tohoku University.
Quick Start
As root increase the number of huge pages on the VH to at least 256 2MB pages per VE core, for example:
sudo sysctl vm.nr_hugepages=$((256*16))
To make this setting permanent create for example a file in /etc/sysctl.d:
echo >/etc/sysctl.d/10-hugepages.conf <<EOF
#
# Set number of huge pages to 4096
#
vm.nr_hugepages = 4096
EOF
and reload the sysctl settings:
sudo sysctl --system
Now you’re ready for VE IO acceleration. Before executing a VE program make the loader preload the accelerated IO library:
export VE_LD_PRELOAD=libveaccio.so.1
Background
The default mechanism for transfering the arguments and buffers for VE system calls offloaded to the VH uses the system or privileged DMA descriptors of each VE. These descriptors require physical addresses for data transfers and the VEOS DMA manager is doing virtual to physical translation each time these transfers are needed. This involves three components:
- the VEOS daemon,
- the system call handler within the pseudo process,
- the vp kernel module.
The accelerated IO mechanism is replacing the read/write family of system calls (read, pread, readv, preadv, write, writev, pwrite, pwritev) by variants that use VHSHM and the VE core’s user DMA descriptors. A system V shared memory buffer is allocated in huge pages on the VH and registered in the DMAATB (address translation buffers), thus made available for user DMA. IO buffer transfers using this mechanism do not need virtual to physical address translation any more and use huge pages on the VH side, thus being less fragmented and faster.
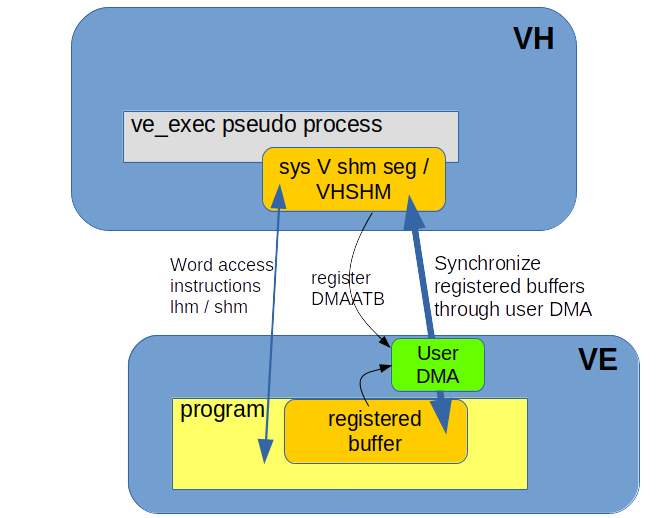
Sketch of VHSHM mechanisms. A system V shared memory segment inside huge pages on VH side is registered with the DMAATB on the VE, another memory buffer on the VE, part of the VE process, is also registered with DMAATB. User DMA can transfer data between the two buffers at very high speed. The VE process can also access the registered VHSHM buffer word-wise through the lhm and shm assembler instructions.
An alternative mechanism: I wrote an optimized version of the DMA manager that uses bulk translations, is aware of huge pages and overlaps translations and transfers. This can speed up all transfers between VH and VE as it still uses system DMA descriptors and works on unregistered buffers. Compared to the DMAATB registered VHSHM this method has higher overhead, since the address translation is done for each transfer. It is available for testing, see for example this post. The RPMs for testing are now available on VEOS-2.0.3 level in the yum repository https://sx-aurora.com/repos/veos/ef_extra. It will eventually make it into the main VEOS release.
NOTE: (June 3, 2019) The improved system DMA patch described above, using bulk virtual to physical translations and overlapping DMA and translations, has been released in VEOS 2.1 and is now available for everybody by default.
Limitations
Currently user DMA descriptors are used also by Infiniband and ScateFS with mechanisms that don’t allow the sharing of the descriptors. Therefore accelerated IO can currently not be used when Infiniband or ScateFS are in use. We expect that this limitation will be lifted towards the end of May 2019.
NOTE: (June 3, 2019) This limitation is indeed lifted with the release of VEOS 2.1.
Performance
The tests summarized in the table below were done with iozone-VE, built from github.com/efocht/iozone-ve.
The test was with one VE only, parameters varied were the IO record
size block and the number of threads. IO was done to /dev/shm,
such that we are not so much limited by a filesystem or disk
bandwidth. Here we mostly care of what performance we can achieve.
A sample call to iozone with record size -r 1m and 2 threads is:
iozone-VE -s 1g -r 1m -t 2 -F /dev/shm/a1 /dev/shm/a2 -i 0 -i 1
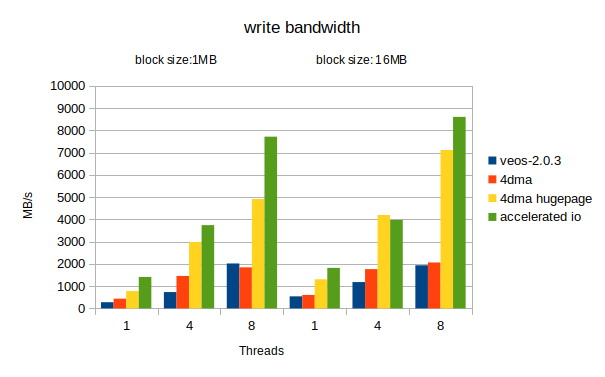
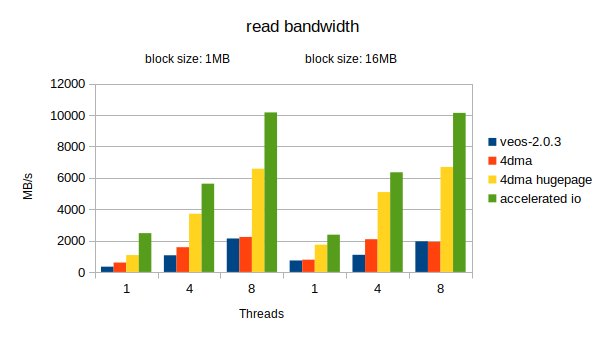
Two block/record sizes were measured: 1MB and 16MB. The 4dma values on huge pages are better with larger record size, they actually converge to the accelerated IO values with transfers in the range of 128-256MB, only these could not be measured with this method due to the way how iozone is allocating its buffers.
The tests were done on four setups:
- plain VEOS 2.0.3,
- VEOS 2.0.3 with the 4dma patches (dma bulk hugepage) using unregistered buffers and system DMA descriptors,
- VEOS 2.0.3 with 4dma on hugepages (prefixed call to iozone by
hugectl --heap, - VEOS 2.0.3 with VE preloaded accelerated IO library.
The results are summarized in the following two figures. Only the initial write and initial read results are shown, the re-writer and re-reader results are systematically higher.
Conclusion
The Accelerated IO feature of libsysve boosts significantly the possible performance of file reads/writes for native VE programs. Whenever possible, use this feature! Do not use the feature when doing MPI over IB or using ScateFS (over IB).
The non-registered system DMA transfers with the 4dma patched VEOS are
also boosting IO performance, especially when huge pages are used on
the VH side. This is easy to achieve by just prepending the program
execution with hugectl --heap or setting the two environment
variables:
export HUGETLB_MORECORE=yes
export LD_PRELOAD=libhugetlbfs.so
Due to its nature, this method is less performant than using registered buffers and user DMA (accelerated IO), but can speed up all VE-VH transfers, therefore it is very much recommended when using VEO or VHcall offloading and it doesn’t interfere with MPI, IB or ScateFS.
The results shown above are of course to be judged with the core performance of the underlying file system in mind. If the application is doing streaming IO which fills the vector host’s pagecache, the underlying filesystem will be the limiting factor, not the bandwidth values shown in the measurements above.
References
Talk by A. Kawahara at the 29th Workshop for Sustained Simulation Performance, March 19-20, 2019, Sendai, Japan.