Erich Focht
Important Notice (March 26 2019)
LLVM has changed the license to Apache 2 while the LLVM-VE repositories at https://github.com/SXAuroraTSUBASAResearch/ were released under the former LLVM license: BSD-2. The change of the license is currently being discussed, until this is solved, the repositories were removed from github. Which means: the links in this post are currently wrong!
People interested in the LLVM-VE development can instead refer to the https://github.com/sx-aurora-dev repositories where the VE development is reflected on the pre-license-change state of LLVM. These repositories (branches develop2) are still under legacy LLVM license.
The list of VE intrinsics is now here.
Introduction
NEC and the Compiler Design Lab of Saarland University (CDL) are collaborating on creating a LLVM backend for the NEC SX-Aurora TSUBASA vector engine (VE). The progress and some results of this work are visible in the repository https://github.com/SXAuroraTSUBASAResearch/llvm and the developments have various directions:
- Supporting a complete set of intrinsics (AKA builtins) for vector operations: intrinsics.html. The current ncc compiler does not support officially intrinsics, and SIMD vector extensions of scalar processors have made programming with intrinsics quite popular. It is much simpler than coding in assembler and allows to fully control the produced vector code.
- Integrating the RegionVectorizer (RV) of Simon Moll into LLVM-VE. RV provides advanced vectorization functionality like outer loop vectorization, nested loop vectorization, whole function vectorization and more.
- Vectorization research at CDL on various topics.
- Pushing the LLVM-SVE effort together with the other architectures that have “scalable vector extensions”: ARM-SVE and RISC-V V. Interestingly the new architecture in the round, NEC SX-Aurora, is the most easily accessible one, being purchasable since February 2018 while ARM-SVE is available for very few people as prototypes, and RISC-V’s vector ISA is currently “paperware”, but seems to have a bright future within the European Processor Innitiative. So LLVM-VE and SX-Aurora are currently most realistic playground for the SVE effort. An RFC has been published at https://reviews.llvm.org/D53613 and is the foundation of a new, SVE related set of intrinsics which are vector length and vector masks aware.

This post describes an easy way to build the LLVM-VE-RV stack and use it for testing and playing with the compiler. The demo was created by Matthias Kurttenacker and Simon Moll and most of the steps described are documented in their README file and come straight from there.
Limitations
At the current stage LLVM-CLANG-VE-RV is experimental, has bugs and does not have full functionality. Without RV LLVM-VE can only produce vector code with the help of the intrinsics. With RV (rvclang) uses a “guided vectorization” approach. Loops/regions preceeded by the directive
#pragma omp simd safelen(256)
will be forcibly vectorized. There is no dependency analysis which would currently enable automatic vectorization.
Right now RV vectorizes only double precision and 64 bit integers on VE and does not implement whole function vectorization, yet. Vector masks are not yet supported.
LLVM currently produces assembler code and uses the NEC ncc compiler for creating object files and binaries. Do have the NEC SX-Aurora SDK installed. Actually binutils-ve could also be used for the assembling step, but the crt* files and some libraries would still be required from ncc.
Installation
Prerequisites
Lots of disk space! At least 12GB! The LLVM and clang repositories are huge and the build requires a lot of disk space.
Connecton to the internet and/or appropriate proxy setup. For git and wget you’d need to set up the http_proxy and ftp_proxy environment variables.
A rather new version of gcc is needed for build, preferable gcc version 7 or above. On CentOS 7 or RHEL 7 use the Software Collections repositories (SCL). On CentOS 7, enable the extras repository, eg. in /etc/yum.repos.d/CentOS-Base.repo. Then install
yum install centos-release-scl
Now install the scl-utils package (this step should be sufficient on RHEL7):
yum install scl-utils
Finally install the new gcc and gcc-c++ packages:
yum install devtoolset-7 devtoolset-7-gcc devtoolset-7-gcc-c++
Download LLVM-VE-RV Demo
The version attached to this post llvmrv_demo-281118a.tar.gz is a repackaged version from http://compilers.cs.uni-saarland.de/people/moll/llvmrv_demo-281118.tar.gz with a changed script and a tuned ncc code example. Download it from the command line:
wget https://sx-aurora.github.io/img/llvmrv_demo-281118a.tar.gz
Build
Enable the new gcc compilers from SCL:
scl enable devtoolset-7 bash
Unpack the demo archive and build the LLVM stack for VE in one (long) step:
tar -xzf llvmrv_demo-281118a.tar.gz
cd workspace
source scripts/bootstrap.sh
Setup Environment
When experimenting later with the LLVM-VE-RV compiler, set the appropriate environment variables and paths by:
source scripts/setup_env.sh
Now you should be able to call clang, which supports --target=ve,
but vectorizes only through explicitly used intrinsics. Or go ahead using rvclang which does guided vectorization of loops preceeded by the directive:
#pragma omp simd safelen(256)
Testing
Compile code with rvclang or clang:
rvclang --target=VE -O2 -fopenmp <FILE.C> -c -o <FILE>.o
Clenshaw Demo
A little example that shows the advantages of outer loop vectorization is included with the demo:
cd demo
make
# The OpenMP code running serially should be given exactly one thread
export OMP_NUM_THREADS=1
# run the LLVM-VE-RV binary
./clenshaw.rv.bin
# run the NCC binary
./clenshaw.ncc.bin
The code is being built with the -fopenmp option and linked with
ncc. It is actually not intended to be OpenMP code at this stage,
but the option is needed in order to interpret the #pragma omp simd
directive correctly. In such a case (compiled with -fopenmp but
actually no OpenMP parallelization inside) it is recommended to
restrict the number of available OpenMP threads to 1, because the
runtime will otherwise create 8 threads, run the code on one and let
the other threads spin around unnecessarily.
Performance of the ncc code is poor. In the same directory I added a hand-optimized version that vectorizes well with ncc but still doesn’t quite reach the RV vectorized version’s performance.
RAJAperf Teaser
In preparation for the LLVMdev conference 2018 in San Jose Simon and Matthias managed to run a set of benchmarks from the RAJA Performance Suite. The figure below is sumarizing the results.
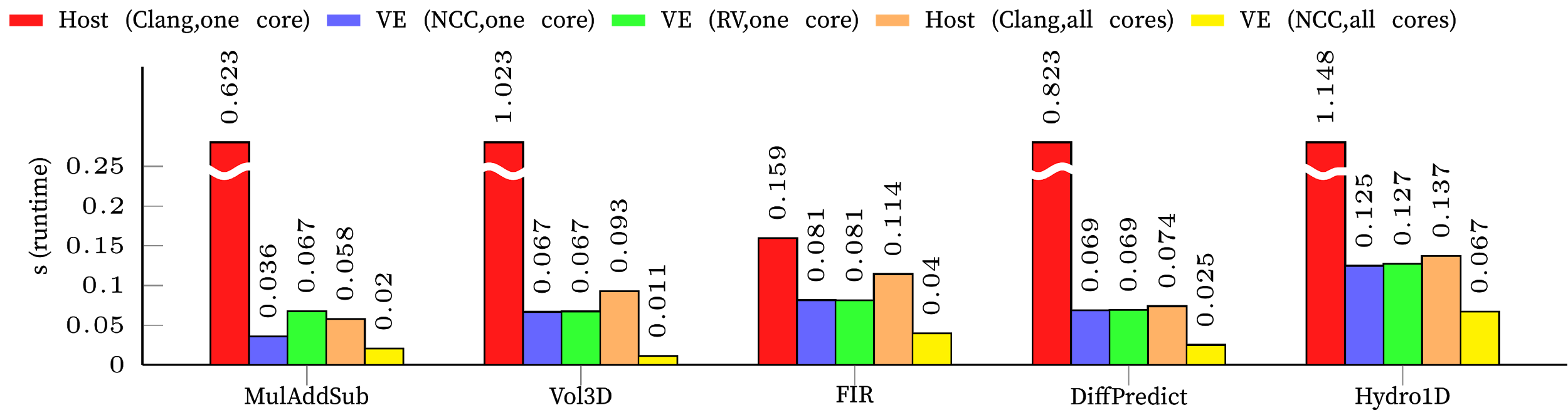
Values in red and orange are from the vector host, a Skylake Gold 6126 CPU at 2.6GHz, the results were produced with AVX512 vectorization, on one core (red) and all 24 cores with Hyperthreading (orange).
Purple columns are results from the SX-Aurora TSUBASA model 10B (1.4GHz), obtained with the ncc compiler on one core. The yellow bars are OpenMP results on 8 cores from the VE with ncc.
Green bars are single core results on the VE using the LLVM-VE-RV compiler.
Conclusion
LLVM offers an excellent platform for compiler research and the LLVM community is spending a lot of effort on vectorization. The LLVM-VE-RV combination is far from being usable for production, but can already show the potential of LLVM and ways how it can supplement NEC’s ncc. If you work with intrinsics, give it a try! If you are more daring, go with guided vectorization with RV! If you have interesting use cases using LLVM-VE, we’d be very pleased to hear about them!